Что такое ansi? Краткая история кодировок
ANSI-люмен (лм, lm), единица измерения - это...
ANSI-люмен – единица измерения освещенности в мультимедийных проекторах, создаваемой лампой при просвечивании через линзу. "Lumen" по-латыни означает "свет", ANSI расшифровывается как "American National Standards Institute". Это стандарт для измерения светового потока, используемый для сравнения проекторов.
Этот параметр был введен в 1992 году Американским институтом Национальных Стандартов в качестве единицы, характеризующей среднюю величину светового потока на контрольном экране с диагональю 40" при минимальном фокусном расстоянии вариообъектива проектора.
Измерение проводится на полностью белой картинке (full white), освещенность экрана измеряется с помощью люксметра в люксах (Lux) в 9 контрольных точках экрана. Значение светового потока рассчитывается как среднее значение этих 9 измерений - умножаются на его площадь и усредняются.
Результирующая световая энергия на экране на каждый квадратный метр указывается в люксах и находится по формуле: люкс = люмен /м². Но измерение люменов/люксов варьируется в зависимости от окружения, настройки прибора и проецируемого изображения, поэтому сегодня в качестве стандарта всеобщее признание получила процедура определения полезного светового потока в ANSI-люменах.
Такое измерение позволяет оценить равномерности распределения светового потока по поверхности экрана. Снижение яркости изображения по его краям называют "Hot Spot" или световым пятном. Равномерность распределения светового потока рассчитывается как соотношение наименьшего и наибольшего из полученных измерений освещенности. В хороших проекторах это значение не падает ниже 70%.
Данная методика точно описывает порядок проведения измерений. При строго определенных условиях окружающей среды и настройках прибора проецируемое на экран изображение делится на девять равных частей, и в каждой из них определяется световая энергия. Среднее значение, полученное из всех девяти замеров и умноженное на площадь экрана в м², дает значение ANSI-люмена.
Интересно, что световой поток, в отличие от освещенности (измеряемой в ANSI-люменах), не зависит от проецируемой площади. К тому же, указанные производителем значения в ANSI-люменах часто опираются на эталонные максимальные настройки, которые редко используются на практике.
Также часто значение в ANSI-люменах является лишь средним значением, поэтому на основе него трудно сделать вывод, насколько хорошо или плохо проектор распределяет свет по поверхности экрана.
Значения ANSI-люменов у цифровых проекторов могут достигать от 900 ANSI-люменов у более старых моделей до 4700 ANSI-люменов у современных мощных приборов. Хороший цифровой проектор для домашнего кинотеатра должен иметь порядка 2000 ANSI-люменов.
Reg.ru: домены и хостинг
Крупнейший регистратор и хостинг-провайдер в России.
Более 2 миллионов доменных имен на обслуживании.
Продвижение, почта для домена, решения для бизнеса.
Более 700 тыс. клиентов по всему миру уже сделали свой выбор.
*Наведите курсор мыши для приостановки прокрутки.
Назад Вперед
Кодировки: полезная информация и краткая ретроспектива
Данную статью я решил написать как небольшой обзор, касающийся вопроса кодировок.
Мы разберемся, что такое вообще кодировка и немного коснемся истории того, как они появились в принципе.
Мы поговорим о некоторых их особенностях а также рассмотрим моменты, позволяющие нам работать с кодировками более осознанно и избегать появления на сайте так называемых кракозябров , т.е. нечитаемых символов.
Итак, поехали...
Что такое кодировка?
Упрощенно говоря, кодировка - это таблица сопоставлений символов, которые мы можем видеть на экране, определенным числовым кодам.
Т.е. каждый символ, который мы вводим с клавиатуры, либо видим на экране монитора, закодирован определенной последовательностью битов (нулей и единиц). 8 бит, как вы, наверное, знаете, равны 1 байту информации, но об этом чуть позже.
Внешний вид самих символов определяется файлами шрифтов , которые установлены на вашем компьютере. Поэтому процесс вывода на экран текста можно описать как постоянное сопоставление последовательностей нулей и единиц каким-то конкретным символам, входящим в состав шрифта.
Прародителем всех современных кодировок можно считать ASCII .
Эта аббревиатура расшифровывается как American Standard Code for Information Interchange (американская стандартная кодировочная таблица для печатных символов и некоторых специальных кодов).
Это однобайтовая кодировка , в которую изначально заложено всего 128 символов: буквы латинского алфавита, арабские цифры и т.д.

Позже она была расширена (изначально она не использовала все 8 бит), поэтому появилась возможность использовать уже не 128, а 256 (2 в 8 степени) различных символов, которые можно закодировать в одном байте информации.
Такое усовершенствование позволило добавлять в ASCII символы национальных языков , помимо уже существующей латиницы.
Вариантов расширенной кодировки ASCII существует очень много по причине того, что языков в мире тоже немало. Думаю, что многие из вас слышали о такой кодировке, как KOI8-R - это тоже расширенная кодировка ASCII , предназначенная для работы с символами русского языка.
Следующим шагом в развитии кодировок можно считать появление так называемых ANSI-кодировок .
По сути это были те же расширенные версии ASCII , однако из них были удалены различные псевдографические элементы и добавлены символы типографики, для которых ранее не хватало "свободных мест".
Примером такой ANSI-кодировки является всем известная Windows-1251 . Помимо типографических символов, в эту кодировку также были включены буквы алфавитов языков, близких к русскому (украинский, белорусский, сербский, македонский и болгарский).
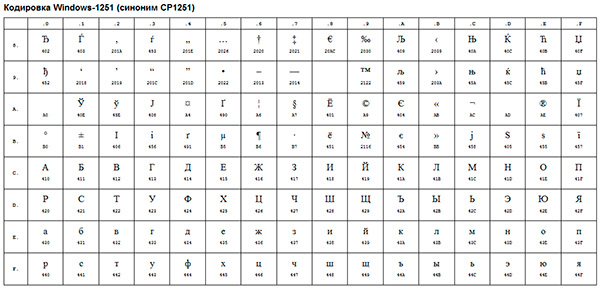
ANSI-кодировка - это собирательное название . В действительности, реальная кодировка при использовании ANSI будет определяться тем, что указано в реестре вашей операционной системы Windows. В случае с русским языком это будет Windows-1251, однако, для других языков это будет другая разновидность ANSI.
Как вы понимаете, куча кодировок и отсутствие единого стандарта до добра не довели, что и стало причиной частых встреч с так называемыми кракозябрами - нечитаемым бессмысленным набором символов.
Причина их появления проста - это попытка отобразить символы, закодированные с помощью одной кодировочной таблицы, используя другую кодировочную таблицу .
В контексте веб-разработки, мы можем столкнуться с кракозябрами, когда, к примеру, русский текст по ошибке сохраняется не в той кодировке, которая используется на сервере .
Разумеется, это не единственный случай, когда мы можем получить нечитаемый текст - вариантов тут масса, особенно, если учесть, что есть еще база данных, в которой информация также хранится в определенной кодировке, есть сопоставление соединения с базой данных и т.д.
Возникновение всех этих проблем послужило стимулом для создания чего-то нового. Это должна была быть кодировка, которая могла бы кодировать любой язык в мире (ведь с помощью однобайтовых кодировок при всем желании нельзя описать все символы, скажем, китайского языка, где их явно больше, чем 256), любые дополнительные спецсимволы и типографику.
Одним словом, нужно было создать универсальную кодировку, которая решила бы проблему кракозябров раз и навсегда .
Юникод - универсальная кодировка текста (UTF-32, UTF-16 и UTF-8)
Сам стандарт был предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (Unicode Consortium, Unicode Inc.), и первым результатом его работы стало создание кодировки UTF-32 .
Кстати, сама аббревиатура UTF расшифровывается как Unicode Transformation Format (Формат Преобразования Юникод).
В этой кодировке для кодирования одного символа предполагалось использовать аж 32 бита , т.е. 4 байта информации. Если сравнивать это число с однобайтовыми кодировками, то мы придем к простому выводу: для кодирования 1 символа в этой универсальной кодировке нужно в 4 раза больше битов , что "утяжеляет" файл в 4 раза.
Очевидно также, что количество символов, которое потенциально могло быть описано с помощью данной кодировки, превышает все разумные пределы и технически ограничено числом, равным 2 в 32 степени. Понятно, что это был явный перебор и расточительство с точки зрения веса файлов, поэтому данная кодировка не получила распространения.
На смену ей пришла новая разработка - UTF-16 .
Как очевидно из названия, в этой кодировке один символ кодируют уже не 32 бита, а только 16 (т.е. 2 байта). Очевидно, это делает любой символ вдвое "легче", чем в UTF-32, однако и вдвое "тяжелее" любого символа, закодированного с помощью однобайтовой кодировки.
Количество символов, доступное для кодирования в UTF-16 равно, как минимум, 2 в 16 степени, т.е. 65536 символов. Вроде бы все неплохо, к тому же окончательная величина кодового пространства в UTF-16 была расширена до более, чем 1 миллиона символов.
Однако и данная кодировка до конца не удовлетворяла потребности разработчиков. Скажем, если вы пишете, используя исключительно латинские символы, то после перехода с расширенной версии кодировки ASCII к UTF-16 вес каждого файла увеличивался вдвое.
В результате, была предпринята еще одна попытка создания чего-то универсального , и этим чем-то стала всем нам известная кодировка UTF-8.
UTF-8 - это многобайтовая кодировка с переменной длинной символа . Глядя на название, можно по аналогии с UTF-32 и UTF-16 подумать, что здесь для кодирования одного символа используется 8 бит, однако это не так. Точнее, не совсем так.
Дело в том, что UTF-8 обеспечивает наилучшую совместимость со старыми системами, использовавшими 8-битные символы. Для кодирования одного символа в UTF-8 реально используется от 1 до 4 байт (гипотетически можно и до 6 байт).
В UTF-8 все латинские символы кодируются 8 битами, как и в кодировке ASCII . Иными словами, базовая часть кодировки ASCII (128 символов) перешла в UTF-8, что позволяет "тратить" на их представление всего 1 байт, сохраняя при этом универсальность кодировки, ради которой все и затевалось.
Итак, если первые 128 символов кодируются 1 байтом, то все остальные символы кодируются уже 2 байтами и более. В частности, каждый символ кириллицы кодируется именно 2 байтами.
Таким образом, мы получили универсальную кодировку, позволяющую охватить все возможные символы, которые требуется отобразить, не "утяжеляя" без необходимости файлы.
C BOM или без BOM?
Если вы работали с текстовыми редакторами (редакторами кода), например Notepad++ , phpDesigner , rapid PHP и т.д., то, вероятно, обращали внимание на то, что при задании кодировки, в которой будет создана страница, можно выбрать, как правило, 3 варианта:
ANSI
- UTF-8
- UTF-8 без BOM
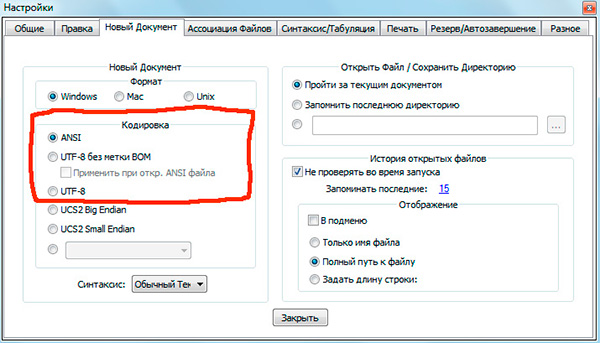


Сразу скажу, что выбирать всегда стоит именно последний вариант - UTF-8 без BOM .
Итак, что же такое BOM и почему нам это не нужно?
BOM расшифровывается как Byte Order Mark . Это специальный Unicode-символ, используемый для индикации порядка байтов текстового файла. По спецификации его использование не является обязательным, однако если BOM используется, то он должен быть установлен в начале текстового файла.
Не будем вдаваться в детали работы BOM . Для нас главный вывод следующий: использование этого служебного символа вместе с UTF-8 мешает программам считывать кодировку нормальным образом , в результате чего возникают ошибки в работе скриптов.
Часто в веб-программировании и вёрстке html-страниц приходится думать о кодировке редактируемого файла — ведь если кодировка выбрана неверная, то есть вероятность, что браузер не сможет автоматически её определить и в результате пользователь увидит т.н. «кракозябры» .
Возможно, вы сами видели на некоторых сайтах вместо нормального текста непонятные символы и знаки вопроса. Всё это возникает тогда, когда кодировка html-страницы и кодировка самого файла этой страницы не совпадают.
Вообще, что такое кодировка текста? Это просто набор символов, по-английски «charset » (character set). Нужна она для того, чтобы текстовую информацию преобразовывать в биты данных и передавать, например, через Интернет.
Собственно, основные параметры, которыми различаются кодировки — это количество байтов и набор спец.символов, в которые преобразуется каждый символ исходного текста.
Краткая история кодировок:
Одной из первых для передачи цифровой информации стало появление кодировки ASCII — American Standard Code for Information Interchange — Американская стандартная кодировочная таблица, принятая Американским национальным институтом стандартов — American National Standards Institute (ANSI) .
В этих аббревиатурах можно запутаться Для практики же важно понимать, что исходная кодировка создаваемых текстовых файлов может не поддерживать все символы некоторых алфавитов (к примеру, иероглифы), потому идёт тенденция к переходу к т.н. стандарту Юникод (Unicode) , который поддерживает универсальные кодировки — Utf-8, Utf-16, Utf-32 и др.
Самая популярная из кодировок Юникода — кодировка Utf-8. Обычно в ней сейчас верстаются страницы сайтов и пишутся разные скрипты. Она позволяет без проблем отображать различные иероглифы, греческие буквы и прочие мыслимые и немыслимые символы (размер символа до 4-х байт). В частности, все файлы WordPress и Joomla пишутся именно в этой кодировке. А также некоторые веб-технологии (в частности, AJAX) способны нормально обрабатывать только символы utf-8.

Установка кодировок текстового файла при создании его обычным блокнотом. Кликабельно
В Рунете же ещё можно встретить сайты, написанные с расчётом на кодировку Windows-1251 (или cp-1251). Это специальная кодировка, предназначенная специально для кириллицы.
Иногда даже достаточно опытный специалист не сразу скажет вам, чему соответствует то или иное значение давления или длины в одной системе значениям в другой системе величин.
Чтобы облегчить вам эту задачу, мы предлагаем таблицы соотношения величин давления и длины в европейской и американской системах с небольшими пояснениями . Но сначала несколько слов о самих стандартах.
DIN - это немецкий стандарт (расшифровывается как Deutsches Institut für Normung , то есть разработанный Германским институтом стандартизации), который разрабатывается строго в рамках положений Международной организации по стандартизации - ISO (International Organization for Standardization).
ANSI – стандарт, принятый в Соединённых Штатах Америки. Расшифровывается как American National Standards Institute , то есть стандарт Американского национального института по стандартизации.
Соответственно, нормы ANSI определяются именно этим институтом, и далеко не всегда между стандартами DIN и ANSI можно проследить точные соответствия в различных сферах.
Перевод единиц давления из ANSI в DIN
Здесь всё просто: если по стандарту ANSI напротив давления стоит цифра 150 - это означает, что номинальное (на которое рассчитана арматура) давление составляет 20 бар, 300 - 50 бар и т.д. Максимальное значение по ANSI Class – 2500 будет равно 420 бар по европейскому стандарту DIN .
Пользуясь этой таблицей, несложно переводить значения давления и обратно: из DIN в ANSI , хотя осуществлять такой перевод нашим инженерам требуется гораздо реже .
Перевод единиц длины из американской системы в европейскую (российскую)
Как известно, американцы всё измеряют дюймами и футами, а мы и европейцы - миллиметрами, сантиметрами и метрами, то есть, как и подавляющее большинство государств мира, мы живём в метрической системе единиц.
Как же переводить дюймы в миллиметры? На самом деле, в этом также нет ничего сложного, достаточно лишь запомнить, что 1 дюйм равняется 25,4 мм. Однако нередко цифрой после запятой пренебрегают и для ровного счёта указывают, что 1 дюйм = 25 мм .
Таким образом, если, например, сечение входного отверстия равно 2 дюймам по американской системе мер, то, переведя по вышеуказанному правилу это значение в нашу систему мер, получаем 50 мм или, что более точно - 51 мм (округлив 50,8 по правилам).
Осталось добавить, что диаметр в технических характеристиках маркируется латинскими буквами DN и нередко указывается именно в дюймах , а давление обозначается при помощи букв PN и указывается чаще всего в барах - во всяком случае, мы используем именно такую маркировку как наиболее удобную .
А следующая таблица поможет вам высчитать не только точное количество миллиметров в одном дюйме (с точностью до тысячной миллиметра), но и поможет узнать, сколько миллиметров содержится, например, в 2,5 дюймах.
Для этого находим колонку 2"" (2 дюйма), а слева ищем значение 1/2. Итого 2,5 дюйма = 63,501 мм, что вполне можно округлить до 64 мм, а, например, 6,25 дюйма (то есть 6 и 1/4) = 158,753 мм или 159 мм.
|
| Дюймы "" в миллиметрах |
|||||||
|
| ||||||||
|
| ||||||||
ANSI это стандарт отображения символов, разработанный American National Standards Institute (код1251). Стандарт ANSI использует только один байт, чтобы представить каждый знак, соответственно ограничен максимумом 256 знаками, в том числе и пунктуации. Коды от 32 до 126 совпадают со стандартом ASCII. Стандарт ASCII (код 688) использовался в DOS, ANSI используется в Windows.
Литература
Архангельский А.Я. Программирование в С++ Builder6. Изд. БИНОМ, 2004.
Архангельский А.Я. С++ Builder6. Справочное пособие. Москва, Изд. БИНОМ, 2004.
Киммел П. BorlandC++5 «BHV-Санкт-Петербург, 2001г.
Климова Л.М. СИ++ Практическое программирование. Решение типовых задач. «КУДИЦ-ОБРАЗ», М.2001.
Культин Н. С/С++ в задачах и примерах. Санкт-Петербург «БХВ-Петербург», 2003.
Павловская Т.А. C/C++ Программирование на языке высокого уровня. Питер, Москва-Санкт-Петербург-… 2005г.
Павловская Т.А., Щупак Ю.А. С++. Объектно-ориентированное программирование. Практикум. СПб., Питер, 2005.
Подбельский В.В. Язык С++ Финансы и статистика, Москва, 2003г.
Поляков А.Ю., Брусенцев В.А. Методы и алгоритмы компьютерной графики в примерах на VisualС++. СПб БХИ-Петербург, 2003г.
Савитч У. Язык С++ курс объектно-ориентированного программирования. Издательский дом Вильямс. Москва-Санкт-Петербург-Киев, 2001г.
Уэллин С. Как не надо программировать на С++. «Питер». Москва-Санкт-Петербург-Нижний Новгород-Воронеж-Новосибирск-Ростов-на-Дону-Екатеринбург-Самара-Киев-Харьков-Минск, 2004.
Шилдт Г. Полный справочник по С++. Изд. Дом «Вильямс» Москва-Санкт-Перербург-Киев, 2003.
Шилдт Г. Самоучитель С/С++ . Санкт-Петербург, «БХВ-Петербург», 2004.
Шилдт Г. Справочник программиста по С/С++ Изд. Дом «Вильямс» Москва-Санкт-Перербург-Киев, 2003.
Шиманович.Л. С/С++ в примерах и задачах. Минск, Новое знание, 2004.
Штерн В. Основы С++. Методы программной инженерии. Изд. Лори.
Почему вместо русских букв в консольном приложении выводится мусор?
и правильно! Текст программы Вы набирали в родном редакторе Visual Studio, используя кодовую страницу 1251, а вывод текста в консольном приложении идет с использованием кодовой страницы 866. Что же делать с этим безобразием? Как известно из любого безвыходного положенния есть по крайней мере 3 выхода. Рассмотрим их по-порядку.
Выход 1
Набрать текст программы в редакторе любого консольного файл-менеджера.
А как же подсветка синтаксиса, вывод по F1 справки по выбранной функции и прочие маленькие прелести, скрашивающие безрадостную жизнь простого программиста? Нет, это выход не для нас.
Выход 2
Если Вы начали писать консольную программу с нуля, он может Вам подойти. Перепишем наш маленький шедевр вот так:
|
#include "stdafx.h" #include "windows.h" int main(int argc, char* argv) char s="Привет всем!"; printf("%s\n", s); |
Ключевое слово здесь CharToOem - именно эта функция и преобразует нашу строку в нужную кодовую страницу. С выводом у нашей программы теперь все нормально.
Но встает следующий вопрос - что делать, если надо перекомпилировать в консольное Windows-приложение Вашу старую DOS-программу на 100000 строк, написанную на Borland C++ 3.1, в которой такая ситуация встречается в каждой второй строке. А ведь придется еще подгонять ее под MS-компилятор, да и пару кусочков кода хочется соптимизировать...
Здесь пожалуй имеет смысл применить ход конем, в смысле









